Making data useful
Making data useful is difficult. The whole point of data engineering/science/analysis/etc is to turn all of the endless piles of information we collect into something that people find valuable. I've spent the better part of the last decade in my career as a software engineer building systems that do this, and I've noticed that it is remarkably difficult to do well. There are many points where the process breaks down, and no silver bullet for fixing them. I've spent a lot of time trying to organize my thoughts on the topic and wrote this down one night:
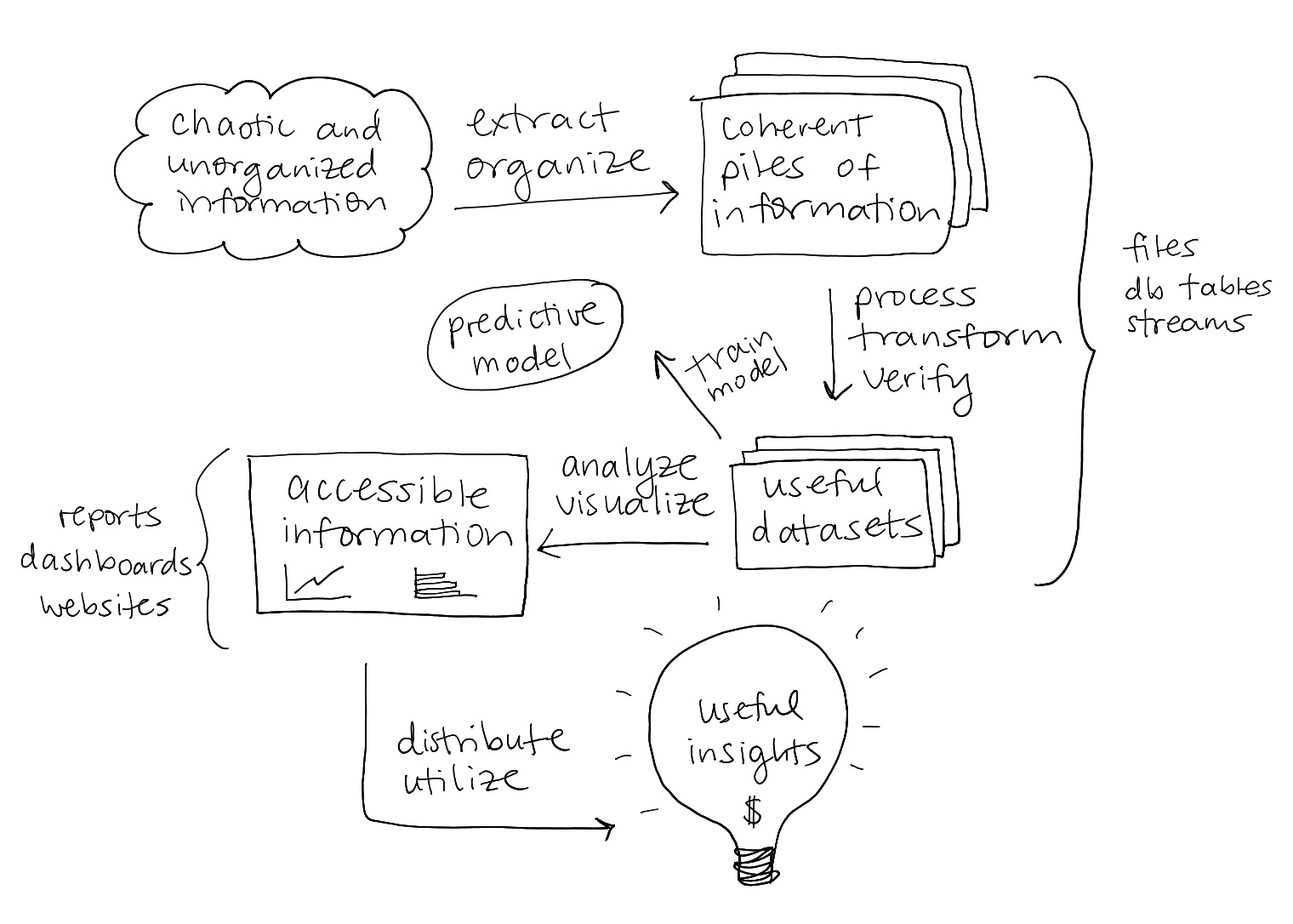
This is one path that the piles of chaotic information we hoard can take to become useful. One problem is that executing all of these steps well requires at minimum a software engineer, a data scientist, and a business analyst.
Without an engineer your data pipelines will be unreliable and incorrect, without a data scientist your analysis will be misleading, and without a business analyst the results will be meaningless and never reach the people who need to see them. That's easily $0.5M/year in headcount alone, a huge expense even if you manage to find a team of open source superstars who can do all of this with free tools and minimal infrastructure.
Another problem is that the steps along this path are not neatly delineated in any way, making them hard to outsource or share. You need the whole team working closely together start to finish to clear a path for your data to flow through the organization.
- A software/data engineer understands how to extract, organize, transform, and store data, but doesn't have a clue what it means. They need input from the business analyst on day one to understand which data should be extracted, and input from the data scientist to understand what format and storage solution will be most convenient for their use. Then they need to come back at the end of the process and help with distribution and dissemination, shipping dashboards, apps, reports, and other ways for non-technical end-users to actually see the results.
- The data scientist needs help from the software engineer to understand why the incoming data is incomplete, inaccurate, and out of date. They need their buy-in to help increase the data's quality, and their help to implement observability and quality checks in a way that isn't slow and expensive. Then once they have clean datasets (no small feat), they need input from the business analyst to understand what they should be looking for.
- The business analyst needs to be giving input every step of the way to make sure the right data gets collected in the first place all the way through to seeing that the right reports are delivered to the right people. They also need to explain the domain and context to their more technical teammates to make sure what they're building is actually valuable to the organization.
There are tools that can help make some of this smoother, but it's a fundamentally complex problem to optimize in a cost-effective way. It's really interesting to think through where the pain points are, and how technology can help address them. This is what's taking up a lot of my bandwidth lately, so if any of it resonates with you I'd love to chat sometime!
Published: 2025-02-26
Tagged: data engineering data
OSS Updates November and December 2024
This is a summary of the open source work I spent my time on throughout November and December 2024. This was the last period of my ongoing funding from Clojurists together. It's been such a magical year in many ways and I'm so grateful to have had the opportunity to spend so much time focusing on open source this year. It was a fantastic experience and I hope to be able to take another professional hiatus at some point in the future to do it again.
I've really enjoyed writing these summaries, too, and I find knowing they're coming helps motivate me to stay more organized and keep better track of things, so I'll probably continue to publish them even though I'll be spending less time on side projects as my focus shifts to other priorities this year.
Sponsors
I always start these posts with a sincere thank you to the generous ongoing support of my sponsors that make this work possible. I can't say how much I appreciate all of the support the community has given to my work and would like to give a special thanks to Clojurists Together and Nubank for providing incredibly generous grants that allowed me reduce my client work significantly and afford to spend more time on projects for the Clojure ecosystem for nearly a year.
If you find my work valuable, please share it with others and consider supporting it financially. There are details about how to do that on my GitHub sponsors page. On to the updates!
BOBKonf 2025
One exciting update is that a workshop I proposed got accepted to BOBKonf, which will be in Berlin next March. It'll be similar to the types of talks and workshops I've been doing over the last couple of years at e.g. the Conj and London Clojurians, of course updated to show off the latest and greatest developments in the Clojure-for-data ecosystem. I spent some time in December beginning work on the content and now I'm in full conference-driven-development mode, figuring out what's realistic to finish in time to demo at the event and what we should consider stable "enough" for now and just include. This preliminary work also sparked a couple of minor conversations, one about quarto theming of Clay notebooks and another about parsing dates from Excel workbooks.
Anyway there are still a couple of months to work on it, which on one hand feels like a long time but on the other hand is also no time at all. Before I know it I'll be landing in Berlin ready to share the wonders of Clojure with a new eager audience.
Clojure Data Cookbook
This has been a very long-running, very ongoing project of mine. The high level goal was always (and still is) to create resources that would allow people to figure out how to be productive with Clojure's data stack. In reality what this particular project morphed into was a process for discovering the gaps in the ecosystem and guiding development of new tools, uncovering missing features to implement or new libraries to write every time I'd start work on a new chapter.
We've come a long way over the past couple of years and there's still work to do but the ecosystem is reasonably mature now. The Noj book has taken on covering a lot of the topics I wanted to document thanks to Daniel Slutsky's incredible efforts at coordinating the community to produce this amazing content. The list of draft articles demonstrates many of the areas where work is still very ongoing in the development of the various libraries. Tutorials are mostly not left unfinished because the authors haven't gotten around to finishing them, but more because the question of what exactly to write about is yet to be answered.
On the Clojure Data Cookbook itself, the current work in progress is available here and includes only sections that document stable and established functionality. The goal of making Clojure's data stack accessible and easy to work with is still at the top of my priority list but conversations are underway about what the best way to do that is in the context of the current ecosystem.
ggclj
Another project I've been poking away at the last couple of months is my implementation of the grammar of graphics in Clojure. Most of my effort here is spent learning more and more about the core concepts of data visualization and how graphics can be represented using a grammar, and then how that grammar could be implemented in an existing programming language. This along with exploring prior implementations in other languages. I have a very rudimentary build process working for transforming an arbitrary dataset into a standardized, graph-able dataset, but nothing yet on the actual graphic rendering. It's very interesting and satisfying but I'm not sure how useful. But, in the spirit of heeding Rich's advice from the last Conj about doing projects for fun, I haven't let it go completely. It's still something I'd love to get working someday.
Reflecting on a year of open source
As I mentioned above I really enjoyed having the time this year to work on so many interesting projects for the Clojure community. It's so rewarding to see how far we've come. Even though it feels like there is still so much to do, I think it's important to reflect on the progress we have made and think about how the problems we encountered along the way shaped the path we took.
When I first started working on the Clojure Data Cookbook, there wasn't even a way to publish a book made out of Clojure files. Clerk was brand new and Clay barely existed. Now we can render a pile of Clojure files as a Quarto book! And the need for better documentation has spurred tons of amazing development in this space. The literate programming story in Clojure is better than in any other language.
We've also made huge strides in connecting the various libraries of the ecosystem together. At the beginning of the year there were many amazing but disconnected libraries. I've been really inspired by the ideas behind the tidyverse and have been trying to communicate the idea of sharing common idioms and data structures. An ecosystem is starting to emerge in Noj that offers a coherent, standardized, shared paradigm for using all of the amazing tools of the Clojure data ecosystem together. The default stack has been chosen, and serious efforts are now underway toward making these libraries feature complete and interoperable. And I plan to continue working on tutorials, guides, and workshops as much as I can to help promote it all.
I'm grateful for all the changes in my life that have taken my time away from working on side projects as much as I used to, like marriage and a great new job, but in many ways I miss doing more of this work and I sincerely hope I find myself in a position to veer off of this "standard" life track in the future to take a period to focus on this kind of stuff full time again. Even better would be figuring out a way to make it sustainable so that I could continue to do it full time. If you have any idea how to make that work, let me know :)
It turns out I am not the kind of market-oriented, entrepreneurially-minded person who can turn coding skills into a business that generates steady income for my family. I like contracting and the slow-and-steady community building type of work that constitutes a career in open source, but unfortunately continuing down this road is just not in the cards for me this year. Though I'll never be able to completely resist working on it whenever I can :) Thanks so much for reading this far, and hope to see you around the Clojureverse!
Published: 2024-12-31
OSS Updates September and October 2024
This is a summary of the open source work I spent my time on throughout September and October 2024. This was a very busy period in my personal life and I didn't make much progress on my projects, but I did have more time than usual to think about things, which prompted many further thoughts. Keep reading for details :)
Sponsors
I always start these posts with a sincere thank you to the generous ongoing support of my sponsors that make this work possible. I can't say how much I appreciate all of the support the community has given to my work and would like to give a special thanks to Clojurists Together and Nubank for providing incredibly generous grants that allowed me reduce my client work significantly and afford to spend more time on projects for the Clojure ecosystem for nearly a year.
If you find my work valuable, please share it with others and consider supporting it financially. There are details about how to do that on my GitHub sponsors page. On to the updates!
Personal update
I'll save the long version for the end but there is one important personal update that's worth mentioning up front: I go by Kira Howe now. I used be known as Kira McLean, and all of my talks, writing, and commits up to this point use Kira McLean, but I'm still the same person! Just with a new name. I even updated my GitHub handle, which went remarkably smoothly.
Conj 2024
The main Clojure-related thing I did during this period was attend the Conj. It's always cool to meet people in person who you've only ever worked with online, and I finally got to meet so many of the wonderful people from Clojure Camp and Scicloj who I've had the pleasure of working with virtually. I also had the chance to meet some of my new co-workers, which was great. There were tons of amazing talks and as always insightful and inspiring conversations. I always leave conferences with tons of energy and ideas. Then get back to reality and realize there's no time to implement them all :) But still, below are some of the main ideas I'm working through after a wonderful conference.
SVGs for visualizing graphics
Tim Pratley and Chris Houser gave a fun talk about SVGs, among other things, that made me realize using SVGs might be the perfect way to implement the "graphics" side of a grammar of graphics.
Some of you may be following the development of tableplot (formerly hanamicloth), in which Daniel Slutsky has been implementing an elegant, layered, grammar-of-graphics-inspired way to describe graphics in Clojure. This library takes this description of a graphic and translates it into a specification for one of the supported underlying Javascript visualization libraries (currently vega-lite or plotly, via hanami). Another way to think about it is as the "grammar" part of a grammar of graphics; a way to declaratively transform an arbitrary dataset into a standardized set of instructions that a generic visualization library can turn into a graphic. This is the first half of what we need for a pure Clojure implementation of a grammar of graphics.
The second key piece we need is a Clojure implementation of the actual graphics rendering. Whether we adopt a similar underlying representation for the data as vega-lite, plotly, or whatever else is less consequential at this stage. Currently we just "translate" our Clojure code into vega-lite or plotly specs and call it a day. What I want to implement is a Clojure library that can take some data and turn it into a visualization. There are many ways to implement such a thing, all with different trade-offs, but Tim and Chouser's talk made me realize SVGs might be a great tool for the job. They're fast, efficient, simple to style and edit, plus they offer potentially the most promising avenues toward making graphics accessible and interactive since they're really just XML, which is semantic, supports ARIA labels, and is easy to work with in JS.
Humble UI also came up in a few conversations, which is a totally tangential concern, but it was interesting to start thinking about how all of this could come together into a really elegant, fully Clojure-based data visualization tool for people who don't write code.
A Clojurey way of working with data
I also had a super interesting conversation on my last night in Alexandria about Clojure's position in the broader data science ecosystem. It's fair to say that we have more or less achieved feature parity now for all the essential things a person working with data would need to do. Work is ongoing organizing these tools into a coherent and accessible stack (see noj), but the pieces are all there.
The main insight I left with, though, was that we shouldn't be aiming for mere feature parity. It's important, but if you're a working data scientist doing everything you already do just with Clojure is only a very marginal improvement and presents a very high switching cost for potentially not enough payoff. In short, it's a tough sell to someone who's doesn't already have some prior reason to prefer Clojure.
What we should do is leverage Clojure's strengths to build tools that could leapfrog the existing solutions, rather than just providing better implementations of them. I.e. think about new ways to solve the fundamental problems in data science, rather than just offering better tools to work within the current dominant paradigm.
For example, a fundamental problem in science is reproducibility. The current ways data is prepared and managed in most data (and regular) science workflows is madness, and versioning is virtually non-existent. If you pick up any given scientific paper that does some sort of data analysis, the chances that you will be able to reproduce the results are near zero, let alone using the same tools the author used. If you do manage to, you will have had to use a different implementation than the authors, re-inventing wheels and reverse-engineering their thought process. The problem isn't that scientists are bad at working with data, it's the fundamental chaos of the underlying ecosystem that's impossible to fight.
If you've ever worked with Python code, you know that dependency management is a nightmare, never mind state management within a single program. Stateful objects are just a bad mental model for computing because they require us to hold more information in our heads in order to reason about a system than our brains can handle. And when your mental model for a small amount of local data is a stateful, mutable thing, the natural inclination is to scale that mental model to your entire system. Tracking data provenance, versions, and lineage at scale is impossible when you're thinking about your problem as one giant, mutable, interdependent pile of unorganized information.
Clojure allows for some really interesting ways of thinking about data that could offer novel solutions to problems like these, because we think of data as immutable and have the tools to make working with such data efficient. None of this is new. Somehow at this Conj between some really interesting talks focused on ways of working with immutable data and subsequent conversations it clicked for me, though. If we apply the same ways we think about data in the small, like in a given program, more broadly to an entire system or workflow, I think the benefits could be huge. It's basically implementing the ideas from Rich Hickey's "Value of values" talk over 10 years ago to a modern data science workflow.
Other problems that Clojure is well-placed to support are:
- Scalability – Current dominant data science tools are slow and inefficient. People try to work around it by implementing libraries in C, Rust, Java, etc. and using them from e.g. Python, but this can only get you so far and adds even more brittleness and dependency management problems to the mix.
- Tracking data and model drift – This problem has a very similar underlying cause as the reproducibility issue, also fundamentally caused by a faulty mental model of data models as mutation machines.
- Testing and validation – Software engineering practices have not really permeated the data science community and as such most pipelines are fragile. Bringing a values-first and data-driven paradigm to pipeline development could make them much more robust and reliable.
Anyway I'm not exactly sure what any of this will look like as software yet, but I know it will be written in Clojure and I know it will be super cool. It's what I'm thinking about and experimenting with now. And I think the key point that thinking about higher-level problems and how Clojure can be applied to them is the right path toward introducing Clojure into the broader data science ecosystem.
Software engineers as designers
Alex Miller's keynote was all about designing software and how they applied a process similar to the one described in Rich Hickey's keynote from last year's conj to Clojure 1.12 (among other things). The main thing I took away from it was that the best use of an experienced software engineer's time is not programming. I've had the good fortune of working with a lot of really productive teams over the years, and this talk made me realize that one thing the best ones all had in common is that at least a couple of people with a lot of experience were not in the weeds writing code all the time. Conversely a common thread between all of the worst teams I've been a part of is that team leads and managers were way too in the weeds, worrying too much about implementation details and not enough about what was being implemented.
I've come to believe that it's not possible to reason about systems at both levels simultaneously. My brain at least just can't handle both the intense attention to detail and very concrete, specific steps required to write software that actually works and the abstract, general conceptual type of thinking that's required to build systems that work. The same person can do both things at different times, but not at the same time, and the cost of switching between both contexts is high.
Following the process described by Rich and then Alex is a really great way to add structure and coherence to what can otherwise come across as just "thinking", but it requires that we admit that writing code is not always the best use of our time, which is a hard sell. I think if we let experienced software engineers spend more time thinking and less time coding we'd end up with much better software, but this requires the industry to find better ways to measure productivity.
Long version of personal updates
As most of you know or will have inferred by now, I got married in September! It was the best day ever and the subsequent vacation was wonderful, but it did more or less cancel my productivity for over a month. If you're into weddings or just want a glimpse into my personal life, we had a reel made of our wedding day that's available here on instagram via our wedding coordinator.
Immediately after I got back from my honeymoon I also started a new job at BroadPeak, which is going great so far, but also means I have far less time than I used for open source and community work. I'm back to strictly evening and weekend availability, and sadly (or happily, depending how you see it) I'm at a stage of my life where not all of that is free time I can spend programming anymore.
I appreciate everyone's patience and understanding as I took these last couple of months to focus on life priorities outside of this work. I'm working on figuring out what my involvement in the community will look like going forward, but there are definitely tons of interesting things I want to work on. I'm looking forward to rounding out this year with some progress on at least some of them, but no doubt the end of December will come before I know it and there will be an infinite list of things left to do.
Thanks for reading all of this. As always, feel free to reach out anytime, and hope to see you around the Clojureverse :)
Published: 2024-10-31