Making data useful
Making data useful is difficult. The whole point of data engineering/science/analysis/etc is to turn all of the endless piles of information we collect into something that people find valuable. I've spent the better part of the last decade in my career as a software engineer building systems that do this, and I've noticed that it is remarkably difficult to do well. There are many points where the process breaks down, and no silver bullet for fixing them. I've spent a lot of time trying to organize my thoughts on the topic and wrote this down one night:
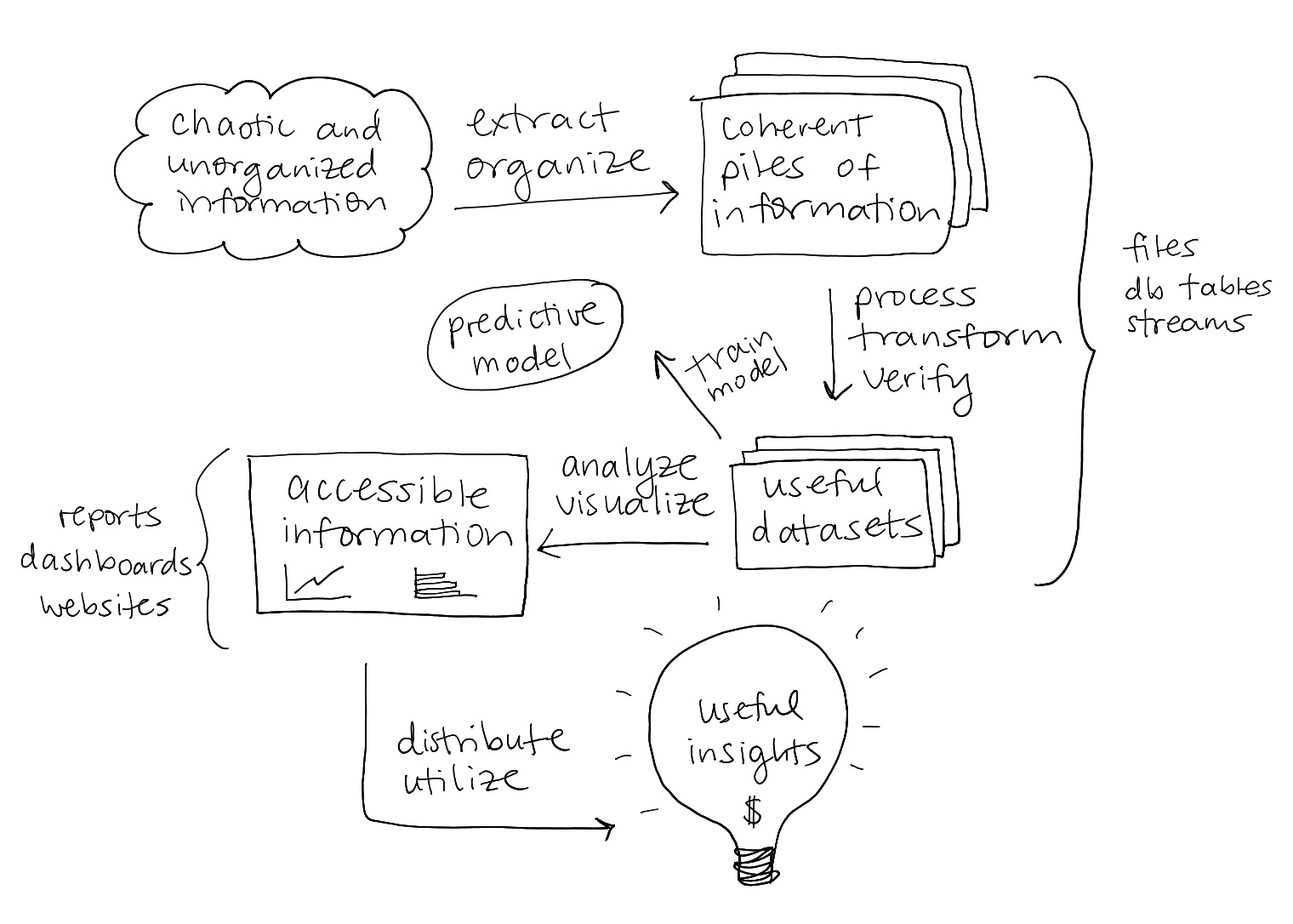
This is one path that the piles of chaotic information we hoard can take to become useful. One problem is that executing all of these steps well requires at minimum a software engineer, a data scientist, and a business analyst.
Without an engineer your data pipelines will be unreliable and incorrect, without a data scientist your analysis will be misleading, and without a business analyst the results will be meaningless and never reach the people who need to see them. That's easily $0.5M/year in headcount alone, a huge expense even if you manage to find a team of open source superstars who can do all of this with free tools and minimal infrastructure.
Another problem is that the steps along this path are not neatly delineated in any way, making them hard to outsource or share. You need the whole team working closely together start to finish to clear a path for your data to flow through the organization.
- A software/data engineer understands how to extract, organize, transform, and store data, but doesn't have a clue what it means. They need input from the business analyst on day one to understand which data should be extracted, and input from the data scientist to understand what format and storage solution will be most convenient for their use. Then they need to come back at the end of the process and help with distribution and dissemination, shipping dashboards, apps, reports, and other ways for non-technical end-users to actually see the results.
- The data scientist needs help from the software engineer to understand why the incoming data is incomplete, inaccurate, and out of date. They need their buy-in to help increase the data's quality, and their help to implement observability and quality checks in a way that isn't slow and expensive. Then once they have clean datasets (no small feat), they need input from the business analyst to understand what they should be looking for.
- The business analyst needs to be giving input every step of the way to make sure the right data gets collected in the first place all the way through to seeing that the right reports are delivered to the right people. They also need to explain the domain and context to their more technical teammates to make sure what they're building is actually valuable to the organization.
There are tools that can help make some of this smoother, but it's a fundamentally complex problem to optimize in a cost-effective way. It's really interesting to think through where the pain points are, and how technology can help address them. This is what's taking up a lot of my bandwidth lately, so if any of it resonates with you I'd love to chat sometime!
Tagged: data engineering data